

Artificial intelligence is often presented as a breakthrough driven by algorithms. In reality, most AI failures can be traced back to something far more foundational: poorly labeled data. A chatbot that misinterprets intent, a recommendation engine that reinforces bias, or a medical AI that overlooks a critical anomaly often shares a common root cause. The training data was incomplete, inconsistent, or inaccurately annotated. Data annotation is the backbone of accuracy in AI systems. It determines whether a model learns meaningful patterns or internalizes confusion. As AI systems move into regulated industries such as healthcare, finance, mobility, and public infrastructure, annotation quality directly impacts safety, compliance, and trust.
This blog explores what data annotation truly involves, the different forms it takes, how it strengthens AI systems, and how organizations can approach it strategically rather than operationally.
What is Data Annotation?
Data annotation is the structured process of labeling raw data so machine learning models can interpret and learn from it. In supervised learning systems, models depend entirely on labeled examples to understand what patterns correspond to which outputs.
At its core, AI annotation translates human understanding into machine-readable signals. When an annotator labels an image with “pedestrian,” the model does not understand the concept of a person walking. It learns statistical associations between pixel patterns and that label.
In practical AI projects, annotation often accounts for a significant portion of development time. Before model training begins, teams must:
- Define labeling objectives
- Design annotation guidelines
- Select annotation tools
- Train annotators
- Establish quality control systems
For example, in a retail product recognition system, annotators may need to differentiate between visually similar packaging variants. In medical imaging, they must carefully outline tumor boundaries at pixel level precision. In financial systems, transaction descriptions must be categorized accurately to train fraud detection models.
Annotation is not simply tagging data. It is a disciplined process that requires domain understanding, consistency, and governance. Without it, supervised AI systems cannot function reliably.
Types of Data Annotation
Different AI use cases require specialized AI annotation techniques. Each type introduces distinct technical and operational challenges.
Image Annotation
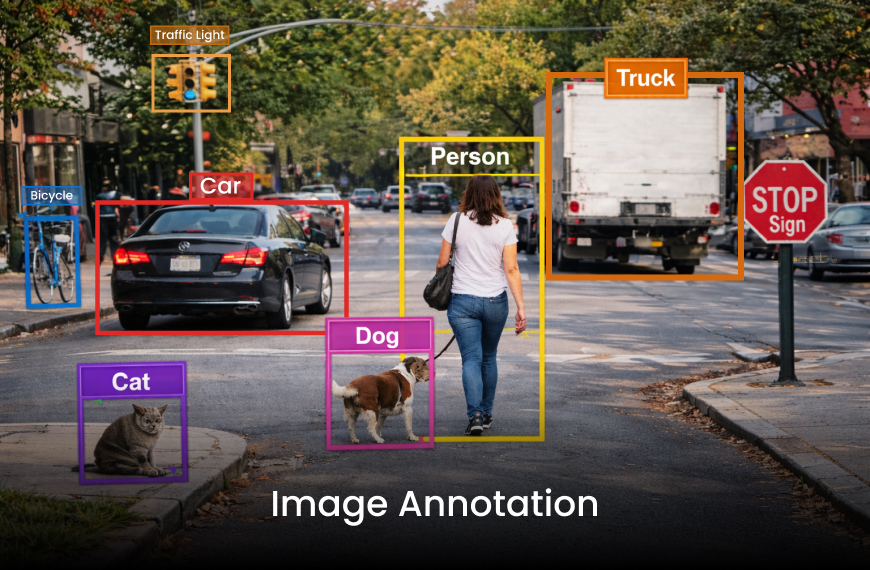
Image annotation is widely used in computer vision applications such as autonomous vehicles, medical diagnostics, manufacturing quality control, and retail analytics. Common approaches include bounding boxes, polygon segmentation, semantic segmentation, key point annotation, and instance masking.
For example, in autonomous driving systems, annotators must identify vehicles, pedestrians, traffic signals, and road boundaries across thousands of frames. A minor labeling inconsistency, such as misclassifying a cyclist as a pedestrian, can influence model behavior in real-world scenarios.
Precision and consistency are critical because computer vision models are highly sensitive to spatial inaccuracies.
Text Annotation

Text annotation powers NLP systems used in chatbots, sentiment analysis, search engines, compliance monitoring, and document classification.
Tasks may include:
- Named entity recognition
- Intent classification
- Sentiment labeling
- Topic categorization
- Relationship extraction
Unlike images, text annotation often requires contextual and cultural understanding. Sarcasm, ambiguous phrasing, or industry jargon can lead to inconsistent labels if guidelines are unclear. For example, in customer service AI, mislabeling “I guess that’s fine” as positive sentiment without considering tone may skew model interpretation.
Audio Annotation
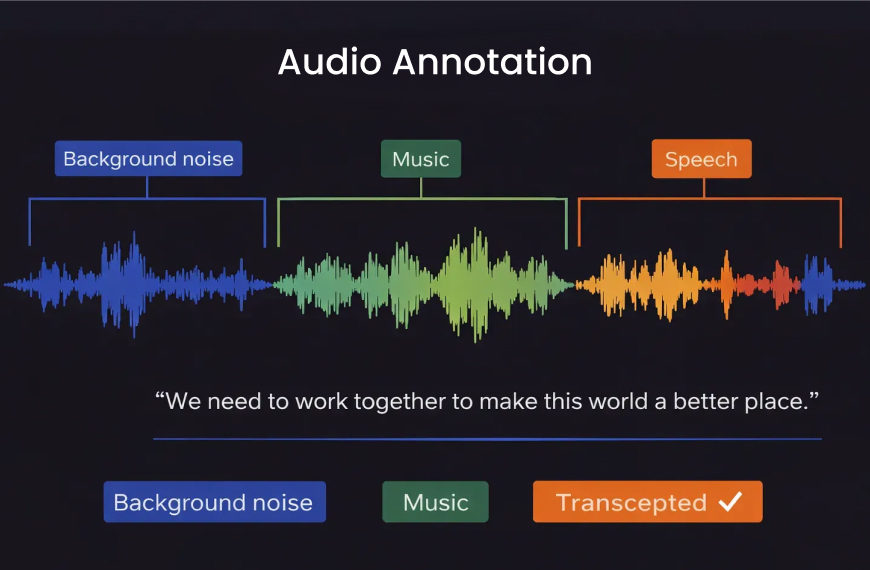
Audio annotation supports speech recognition, voice assistants, call center analytics, and emotion detection systems. Tasks include transcription, speaker diarization, timestamp alignment, and acoustic labeling.
Accent variation, background noise, overlapping speech, and language diversity introduce complexity. High quality audio annotation often requires trained linguists or native speakers to ensure reliability.
Video Annotation

Video annotation extends image labeling across time sequences. It is used in surveillance, sports analytics, retail footfall tracking, and autonomous navigation. Annotators must track object movement frame by frame while maintaining consistency. Temporal accuracy matters. Misalignment in a few frames can degrade tracking models significantly.
3D and Sensor Data Annotation

Emerging AI systems rely on LiDAR, radar, and 3D sensor inputs. Annotation here involves labeling spatial data points in three dimensional space. These tasks are technically demanding and require specialized tools. Errors in 3D annotation can directly impact navigation accuracy in robotics and mobility systems.
Key Benefits of High Quality Data Annotation for AI
High quality AI annotation influences AI performance far beyond training metrics.
Improved Model Generalization
When labels are consistent and precise, models learn underlying patterns rather than memorizing noise. This improves performance on unseen data. Generalization is critical for real-world deployment. AI systems must handle variations they were not explicitly trained on.
Reduced Bias and Ethical Risk
Structured guidelines and diverse datasets reduce the likelihood of systemic bias entering the model. For example, balanced demographic representation in facial recognition datasets improves fairness and reduces discriminatory outcomes.
Faster Iteration Cycles
Clean datasets accelerate training convergence. Teams spend less time debugging unpredictable model behavior caused by noisy labels.
Lower Long-Term Costs
Correcting model errors after deployment requires retraining, data reprocessing, and sometimes reputational repair. Investing in annotation quality early prevents compounding downstream expenses.
Regulatory Readiness
As AI regulations expand globally, documentation of annotation workflows becomes increasingly important. Audit trails, version controlled guidelines, and quality benchmarks provide transparency and compliance support.
The Role of Accurate Data Annotation in Improving AI Models
Accurate data annotation directly shapes how AI models behave in production environments. When labels are consistent, models learn clear decision boundaries. When labels are inconsistent, models struggle with ambiguity.
For instance, in fraud detection systems, if certain borderline cases are inconsistently labeled as fraudulent or legitimate, the model’s threshold calibration becomes unstable. This increases false positives or false negatives. In healthcare AI, inconsistent labeling of imaging abnormalities can alter diagnostic sensitivity. This has direct patient safety implications.
Accurate annotation improves AI models in measurable ways:
- It reduces prediction variance
- It stabilizes probability distributions
- It strengthens edge case handling
- It increases confidence calibration
One often overlooked factor is annotation drift. Over time, changes in guidelines or annotator interpretation can introduce inconsistencies. Regular recalibration sessions and blind sampling audits help prevent this issue.
Data Annotation is the Backbone of Accuracy not because it supports AI indirectly, but because it defines what the model learns in the first place.
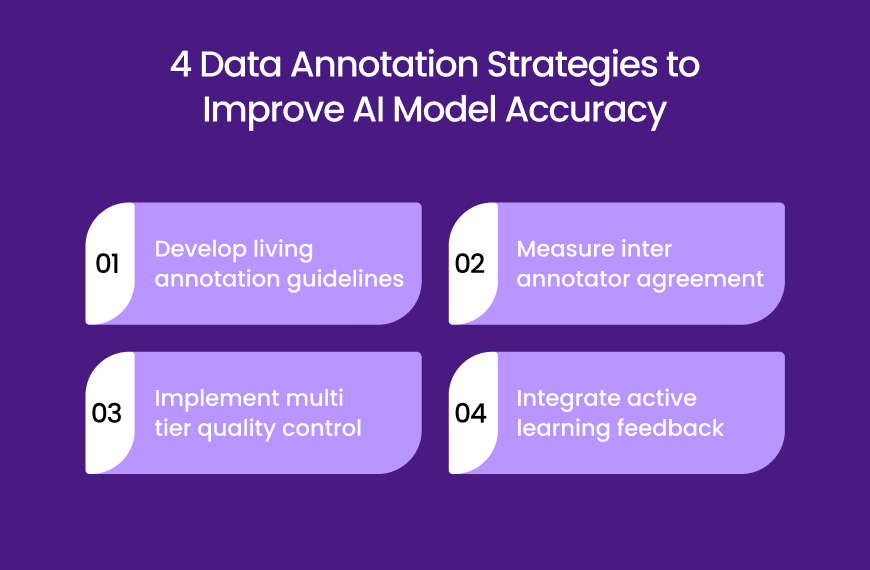
4 Data Annotation Strategies to Improve AI Model Accuracy
Organizations that treat annotation strategically outperform those that view it as a repetitive task. The following four strategies consistently improve AI model performance.
1. Develop Living Annotation Guidelines
Annotation documentation should include detailed instructions, visual examples, edge case explanations, and revision histories.
Guidelines must evolve as models improve and new data patterns emerge. Static documentation leads to inconsistency.
2. Measure Inter Annotator Agreement
Agreement scoring identifies ambiguity in labeling rules. Low agreement often signals unclear definitions or insufficient training. Addressing disagreement early protects dataset integrity.
3. Implement Multi Tier Quality Control
High impact projects benefit from layered review structures. Primary annotators label data. Secondary reviewers validate samples. Senior domain experts audit critical cases. This hierarchy significantly reduces systemic labeling errors.
4. Integrate Active Learning Feedback
Active learning systems identify uncertain predictions and route them back for human review. This targeted annotation approach improves dataset efficiency and focuses effort where it matters most.
Why Partnering with a Data Annotation Service Provider like Noseberry Digitals
As AI projects scale, managing annotation internally becomes resource intensive. Many organizations turn to data annotation outsourcing services to handle large volumes efficiently. However, the value of outsourcing goes beyond cost savings.
Access to Specialized Expertise
A professional data annotation service provider like Noseberry Digitals invests in trained annotators and domain specialists. This is particularly valuable in industries such as healthcare, finance, and legal technology where contextual accuracy matters.
Scalable Infrastructure
Large annotation projects require secure platforms, quality dashboards, and workforce management systems. Established providers bring operational maturity that internal teams may lack.
Consistency at Scale
Experienced providers maintain standardized workflows that preserve quality across large datasets. Consistency across millions of data points is difficult without structured systems.
Data Security and Compliance
Reputable providers implement strict confidentiality protocols and compliance standards, reducing legal risk.
The key to successful collaboration is alignment. Organizations must clearly communicate objectives, quality benchmarks, and review processes. Outsourcing should be treated as a partnership, not a transactional exchange.
Conclusion
Artificial intelligence does not improve by accident. It improves through disciplined data preparation. Data annotation defines what AI systems learn, how they generalize, and whether they operate ethically and reliably. Organizations that invest in structured annotation strategies, continuous quality monitoring, and thoughtful partnerships build AI systems that are stable, trustworthy, and scalable.
In the evolving AI landscape, competitive advantage will not belong solely to those with advanced algorithms. It will belong to those who build stronger foundations beneath them.


